linux 下一切皆文件!换言之就是linux操作系统将系统中的一切都作为文件来管理。在windows中我们常见的硬件设备(打印机、网卡、声卡...)、磁盘分区等,在linux中统统都被视作文件,对设备、分区的访问就是读写对应的文件。
“一切皆是文件”是 Unix/Linux 的基本哲学之一。不仅普通的文件,目录、字符设备、块设备、 套接字等在 Unix/Linux 中都是以文件被对待;它们虽然类型不同,但是对其提供的却是同一套操作界面。操作文件时需先打开;打开文件时,VFS 会知道该文件对应的文件系统格式;当VFS把控制权传给实际的文件系统时,实际的文件系统再做出具体区分,对不同的文件类型执行不同的操作。这也就是“一切皆是文件”的根本所在。
扇区(Sector)
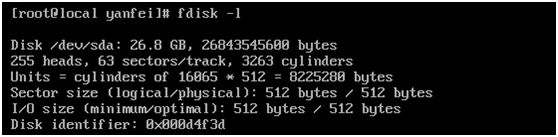
df 命令用于查看已挂载磁盘的总容量、使用容量、剩余容量等,可以不加任何参数,默认是按k为单位显示的。
3.5.3 ext3 文件系统ext3 文件系统向标准 ext2 文件系统添加了日志功能,因此是一个非常稳定的文件系统的一个演化发展。它在大多数情况下提供合理的性能并且仍旧在改进。由于它在可靠的 ext2 文件系统上添加了日志功能,因此可以将现有 ext2 文件系统转换为 ext3 文件系统,并且在必要时还可以转换回来。
一个分区可以挂在多个目录,但反过来一个目录只能是一个分区的挂载点。
XFS 文件系统拥有日志功能,包含一些健壮的特性,并针对可伸缩性进行了优化。XFS 通常是相当快的。在大文件操作方面,XFS 在所有测试中一直处于领先地位。XFS 的性能非常接近 ReiserFS,并在大多数测试指标上都超过了 ext3。
当在用户应用程序调用文件 I/O read()操作时,系统调用 sys_read() 被激发,sys_read() 找到文件所在的具体文件系统,把控制权传给该文件系统,最后由具体文件系统与物理介质交互,从介质中读出数据。
候选的磁盘分区方案:
第二步,找到目标磁道后通过盘面旋转,将目标扇区移动到磁头的正下方。

VFS 是底层文件系统的主要接口,它是 Linux 内核中的一个软件抽象层。。这个组件导出一组接口,然后将它们抽象到各个文件系统,各个文件系统的行为可能差异很大。有两个针对文件系统对象的缓存(inode 和 dentry)。它们缓存最近使用过的文件系统对象。因为有 VFS 存在,Linux 允许众多不同的文件系统共存,并支持跨文件系统的文件操作。它通过一些数据结构及其方法向实际的文件系统如 ext2,vfat 提供接口机制。
在有多个盘片构成的盘组中,由不同盘片的面,但处于同一半径圆的多个磁道组成的一个圆柱面(Cylinder)。所有盘面上的同一磁道构成一个圆柱,通常称做柱面(Cylinder),每个圆柱上的磁头由上而下从“0”开始编号。数据的读/写按柱面进行,即磁 头读/写数据时首先在同一柱面内从“0”磁头开始进行操作,依次向下在同一柱面的不同盘面即磁头上进行操作,只在同一柱面所有的磁头全部读/写完毕后磁头 才转移到下一柱面,因为选取磁头只需通过电子切换即可,而选取柱面则必须通过机械切换。电子切换相当快,比在机械上磁头向邻近磁道移动快得多,所以,数据 的读/写按柱面进行,而不按盘面进行。也就是说,一个磁道写满数据后,就在同一柱面的下一个盘面来写,一个柱面写满后,才移到下一个扇区开始写数据。读数 据也按照这种方式进行,这样就提高了硬盘的读/写效率。
2. 格式化分区:mkfs -t ext3 /dev/sda1
编辑 /etc/fstab 文件,添加:/dev/sda1 /test ext3 defaults 1 1,重启则发选已经挂载上去。
格式化命令:
因此,磁盘IO时的过程包括:
/dev/hdb 1st (Primary) IDE controller Slave
目录只占磁盘里的一个inode,存放文件属性等信息。
一个分区挂载在一个已存在的目录上,这个目录可以不为空,但挂载后这个目录下以前的内容将不可用。对于其他操作系统建立的文件系统的挂载也是这样,卸载后,目录以前的文件都还在,不会有任何丢失。
针对不同的挂载点的特性分配合适的文件系统以合理发挥性能,比如对 /var 使用reiserfs,对 /home 使用xfs,对 / 使用ext4。
3. 挂载 mount /dev/sda1 /test
文件系统是对一个存储设备上的数据和元数据进行组织的机制。它的最终目的是把大量数据有组织的放入持久性(persistant)的存储设备中,比如硬盘和磁盘。文件系统(file system)是就是文件在逻辑上组织形式,它以一种更加清晰的方式来存放各个文件。数据被存入到某个分区中。一个典型的Linux分区(partition)包含有下面各个部分:
第一步,首先是磁头径向移动来寻找数据所在的磁道。这部分时间叫寻道时间。
在Linux中,我们通过解析路径,根据沿途的目录文件来找到某个文件。目录中的条目除了所包含的文件名,还有对应的inode编号。当我们输入$cat /var/test.txt时,Linux 将在根目录文件中找到 var 这个目录文件的inode编号,然后根据 inode 合成 var 的数据。随后,根据 var 中的记录,找到 text.txt 的 inode 编号,沿着 inode 中的指针,收集数据块,合成 text.txt 的数据。整个过程中,会参考三个inode:
读取文件:

linux 下一切皆文件!换言之就是linux操作系统将系统中的一切都作为文件来管理。在windows中我们常见的硬件设备(打印机、网卡、声卡...)、磁盘分区等,
![]()
我们坚持原创,我们尊重艺术!
经营项目:雕塑定制,油画定制,3d画设计制作,字画装裱,壁画手绘墙,陶瓷定制,名人字画出售。

